
CQRS, ou Command Query Responsibility Segregation, est une architecture où la partie Command (écriture) et la partie Query (lecture) du système sont séparées.
J’ai eu la chance d’assister récemment à une présentation de Tomasz Jaskula nommée Recettes CQRS, pour bien cuisiner son architecture. Je l’ai beaucoup appréciée, notamment car on voit les différentes étapes pour arriver à une architecture CQRS / Event Sourcing / DDD à partir d’une architecture N-Tiers “classique”.
L’objectif de cet article est de présenter ma compréhension et mon avis sur le CQRS en particulier.
Mise en place
Le passage d’une architecture N-Tiers à une architecture CQRS est relativement simple, comme montré ci-dessous.
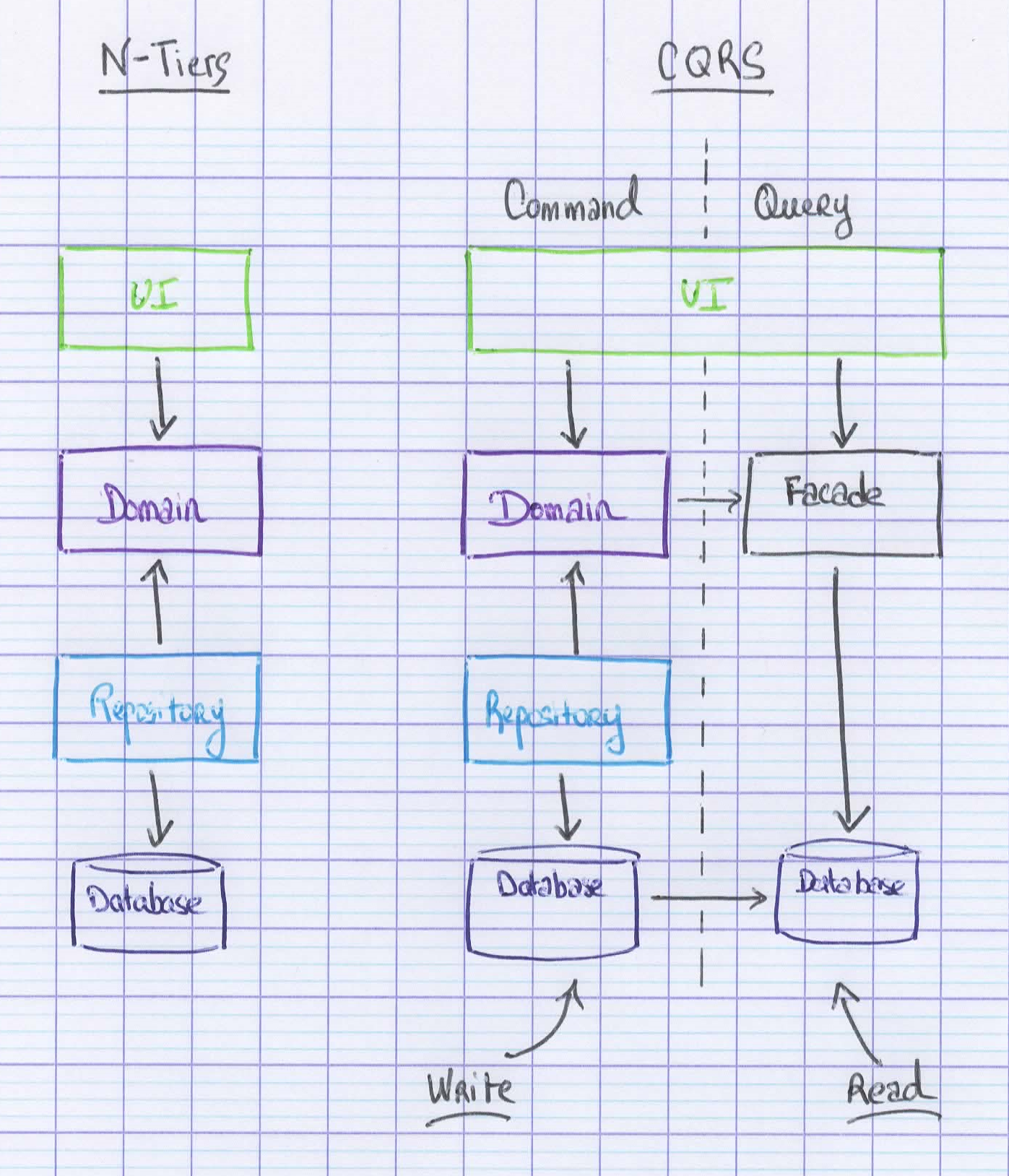
Concrètement, je pense que cela consiste tout d’abord à identifier les requêtes associées à chacune des vues et à les regrouper dans des classes dédiées. Ces classes formeront la partie lecture de l’architecture.
Ensuite, les objets retournés par ces requêtes sont remplacés par des DTO qui ne contiennent plus que les informations nécessaires à la construction de la vue associée.
Finalement, le modèle d’écriture peut être débarrassé de toutes ses méthodes et propriétés transitoires, qui ne servaient seulement qu’à de la lecture.
Cette architecture apporte des avantages en termes de maintenabilité et de performances mais peut encore être améliorée.
Conséquences
Augmentation de la maintenabilité
L’application du CQRS simplifie grandement le modèle d’écriture. En effet, il arrive souvent que des propriétés transient soient calculées uniquement pour de l’affichage. Ces propriétés, ainsi que les méthodes associées, alourdissent le modèle et n’apportent pas de valeur pour les traitements métiers.
Les services, parfois très lourds, sont remplacés par des classes spécialisées, concises et cohérentes. Ceci permet donc de mieux respecter le Single Responsibility Principle (SRP) ainsi que l’Interface Segregation Principle (ISP). De plus, il n’y aura plus de méthodes “passe-plat” dans les services car celles-ci seront directement implémentées dans les classes de lecture.
Finalement, l’ajout d’une nouvelle vue ne risque pas d’engendrer de régression car il s’agit simplement d’ajouter une nouvelle classe de lecture ainsi que le(s) DTO associé(s), sans modifier le reste.
Amélioration des performances
La séparation de la lecture et de l’écriture permet d’améliorer les performances du système. En effet, il est difficile d’optimiser à la fois la mise à jour et la lecture dans une base de données. Par exemple, l’ajout d’un index améliore grandement les performances à la lecture mais affecte sensiblement l’écriture.
Ces deux opérations pouvant être séparées dans deux bases différentes, il devient alors possible d’optimiser chacune des bases pour son utilisation particulière. De plus, les données de la base de lecture peuvent être dénormalisées, ce qui simplifie grandement les requêtes effectuées et peut les rendre bien plus efficaces.
Pistes d’amélioration
Selon moi, la principale difficulté du CQRS réside dans l’alimentation de la base de lecture à partir de la base d’écriture. Il est possible de la réaliser à l’aide d’un batch qui se lancera régulièrement. Cependant, l’application ne serait plus en temps réel.
Une alternative pourrait alors être d’écrire dans la base de lecture en même temps que dans la base d’écriture. Cette solution n’est pas idéale pour moi car elle ne supprime pas le couplage entre la lecture et l’écriture. De plus, si cette solution est implémentée via un mécanisme synchrone, il est impossible de paralléliser les traitements lorsque le système est très chargé, ce qui peut affecter nettement les performances.
La solution d’utiliser des événements asynchrones proposée par Tomasz me semble la plus adaptée pour résoudre ces problèmes. Comme il l’a indiqué, il faut néanmoins analyser le besoin et la stratégie d’entreprise ainsi que les ressources disponibles avant de se lancer dans la mise en place d’une telle architecture.
Conclusion
Le CQRS est une architecture simple à comprendre et à mettre en place. Elle permet d’augmenter la maintenabilité du code et d’améliorer les performances des vues. Je pense qu’elle peut être mise en place sur un projet (ou une de ses parties) dès que les vues se multiplient et que les services commencent à grossir.